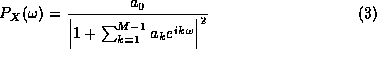
 |
 |
 |
 |
The toolkit also provides spectral estimation by MEM. Given a
stationary time series X, and its first M auto-correlation
coefficients
![]() , the purpose of MEM is to obtain the spectral
density PX
by determining the most random (i.e. with the fewest
assumptions) process, with the same auto-correlation coefficients as
X. In terms of information theory, this is the notion of maximal
entropy, hence the name of the method.
, the purpose of MEM is to obtain the spectral
density PX
by determining the most random (i.e. with the fewest
assumptions) process, with the same auto-correlation coefficients as
X. In terms of information theory, this is the notion of maximal
entropy, hence the name of the method.
The entropy h of a Gaussian process is given by
![]()
![]()
The MEM is very efficient for detecting frequency lines in stationary time series. However, if this time sereis is not-stationary, misleading results can occur, with little chance of being detected otherwise than by cross-checking with other techniques.
The art of using MEM resides in the appropriate choice of M, i.e. the order of regression of Y. The behavior of the spectral estimate depends on the choice of M: it is clear that the number of poles (or even maxima) of Eq. (3) depends on the order of regression M and the auto-regression coefficients ak , so that, for a given time series, the number of peaks will increase with M! Therefore, a trade-off between a good resolution (high M) and few spurious peaks (low M) has to be found. A few guides are provided by the default values of the toolkit (i.e. M should not exceed half the length of the time series).
The weaknesses can be remedied partly by (a) determining which peaks survive reductions in M, (b) comparing MEM spectra to those produced by correlogram and MTM which generally should not share spurious peaks with MEM, and (c) using SSA to pre-filter the series and thus to decompose the original series into several components, each of which contains only a few harmonics (so that small M values can be chosen; see Penland et al., 1991). The ease with which these various analyses can be interwoven in the Toolkit was a major motivation for its development.
|
|
|
|
|