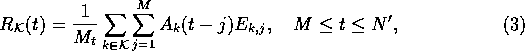
 |
 |
 |
 |
Colebrook (1978) applied a form of SSA to biological oceanography and noted the duality between principal component analysis (PCA) in the space and time domain. Broomhead and King (1986: BK hereafter) applied the ``method of delays'' of dynamical systems theory to estimate the dimension of and reconstruct the Lorenz attractor using singular-value decomposition (SVD) on the trajectory matrix formed by lagged copies of a single series obtained from the system.
Vautard and Ghil (1989: VG hereafter) realized the formal similarity between classical lagged-covariance analysis and the method of delays. They exploited this similarity further by pointing out that pairs of SSA eigenmodes corresponding to nearly equal eigenvalues and associated (temporal) principal components that are nearly in phase quadrature can represent efficiently a nonlinear, anharmonic oscillation. This is due to the fact that a single pair of data-adaptive eigenmodes can capture the basic periodicity of a boxcar or seesaw-shaped oscillation, say, rather than necessitate the many overtones that will appear in methods with fixed basis functions.
There are three basic steps in SSA: i) embedding the sampled time
series in a vector space of dimension M; ii) computing the ![]() lag-covariance matrix
lag-covariance matrix ![]() of the data; and iii) diagonalizing
of the data; and iii) diagonalizing
![]() .
.
Step (i): The time
series ![]() is embedded into a vector space of dimension
M by considering M lagged copies
is embedded into a vector space of dimension
M by considering M lagged copies ![]() thereof. The choice of the dimension M is not obvious.
Vautard et al. (1992)
suggest that SSA is typically successful at analyzing periods in the range
(M/5, M).
thereof. The choice of the dimension M is not obvious.
Vautard et al. (1992)
suggest that SSA is typically successful at analyzing periods in the range
(M/5, M).
Step (ii): One defines the ![]() lag-covariance matrix estimator
lag-covariance matrix estimator
![]() . There are two distinct methods used widely to define
. There are two distinct methods used widely to define
![]() ,
due to BK and VG, respectively. In the BK algorithm, a window of
length M is moved along the time series, producing a sequence of
,
due to BK and VG, respectively. In the BK algorithm, a window of
length M is moved along the time series, producing a sequence of ![]() vectors in the embedding space. This sequence is used to obtain the
vectors in the embedding space. This sequence is used to obtain the
![]() trajectory matrix
trajectory matrix ![]() , where the i-th row is the i-th
view of the time series through the window.
In this approach,
, where the i-th row is the i-th
view of the time series through the window.
In this approach, ![]() is defined by:
is defined by:
In the VG algorithm, ![]() is estimated directly from
the data
as a Toeplitz matrix with constant diagonals.
Both the BG and VG algorithms are implemented in the SSA-MTM Toolkit.
is estimated directly from
the data
as a Toeplitz matrix with constant diagonals.
Both the BG and VG algorithms are implemented in the SSA-MTM Toolkit.
Step (iii): The covariance matrix calculated from the N
sample points, using the BK or VG algorithm, is then diagonalized and
the eigenvalues ![]() are ranked in decreasing order.
The eigenvalue
are ranked in decreasing order.
The eigenvalue ![]() gives the variance of the time series in the
direction specified by the corresponding eigenvector
gives the variance of the time series in the
direction specified by the corresponding eigenvector ![]() ; the square
roots of the eigenvalues are called singular values and the set
; the square
roots of the eigenvalues are called singular values and the set
![]() the singular spectrum. These terms
give SSA its name; BK showed how to obtain the set
the singular spectrum. These terms
give SSA its name; BK showed how to obtain the set ![]() by SVD applied to the trajectory matrix
by SVD applied to the trajectory matrix ![]() .
VG called the
.
VG called the ![]() 's
empirical orthogonal functions (EOFs), by analogy with the
meteorological term used when applying PCA in the spatial
domain.
's
empirical orthogonal functions (EOFs), by analogy with the
meteorological term used when applying PCA in the spatial
domain.
If we arrange and plot the singular values in decreasing order, one can often distinguish an initial steep slope, representing the signal, and a (more or less) ``flat floor,'' representing the noise level (Vautard and Ghil, 1989) To correctly separate signal from noise, this visual observation of the spectral plot must be confirmed by suitable criteria for statistical significance as discussed later.
Once these three steps have been completed, a number of other
interesting results can be obtained. For each EOF ![]() with
components
with
components
![]() , we can construct the time series of length N'
given by:
, we can construct the time series of length N'
given by:
called the k-th principal component (PC). It represents the projection of the original time series onto the k-th EOF. The sum of the power spectra of the PCs is identical to the power spectrum of the time series x(t) (Vautard et al., 1992); therefore we can study separately the spectral contribution of the various components. The PCs, however, have length N', not N, and do not contain phase information.
In order to extract time series of length N, corresponding to a
chosen subset of ![]() eigenelements, the associated PCs are
combined to form the partial reconstruction
eigenelements, the associated PCs are
combined to form the partial reconstruction ![]() of the original time series x(t).
Over the central part of the time series,
of the original time series x(t).
Over the central part of the time series,
and ![]() ; near the endpoints
(
; near the endpoints
( ![]() or
or ![]() ),
the summation in j extends from 1 to t or from (t-N+M) to
M and
),
the summation in j extends from 1 to t or from (t-N+M) to
M and ![]() (Vautard et al., 1992).
These series of length
N are called reconstructed components (RCs). They have the important
property of preserving the phase of the time series; therefore x(t) and
(Vautard et al., 1992).
These series of length
N are called reconstructed components (RCs). They have the important
property of preserving the phase of the time series; therefore x(t) and
![]() can be superimposed.
When
can be superimposed.
When ![]() contains the components of a
single eigenvector
contains the components of a
single eigenvector ![]() ,
, ![]() is called the k-th
RC. If we denote it by
is called the k-th
RC. If we denote it by ![]() , one can show that
, one can show that
that is, the time series can be reconstructed completely by summing its RCs, without losing any information. Allen et al. (1992a) noted that, when a linear trend is present, reconstruction based on the BK algorithm has certain advantages near the endpoints of the sample.
The correct partial reconstruction of the signal, i.e.,
the reconstruction over the correct set
![]() of EOFs, yields the optimal
signal-to-noise (S/N) enhancement with respect to white noise. MEM spectral
estimation will work very well on this clean signal (Penland et al., 1991,
Keppenne and Ghil, 1992) which,
unlike the raw time series, is band limited. As a result, a low-order
AR-process fit can yield good spectral resolution, without spurious peaks.
of EOFs, yields the optimal
signal-to-noise (S/N) enhancement with respect to white noise. MEM spectral
estimation will work very well on this clean signal (Penland et al., 1991,
Keppenne and Ghil, 1992) which,
unlike the raw time series, is band limited. As a result, a low-order
AR-process fit can yield good spectral resolution, without spurious peaks.
In order to perform a good reconstruction of the signal or of its oscillatory part(s) several methods - either heuristic or based on Monte Carlo ideas - have been proposed for S/N separation or for reliable identification of oscillatory pairs and trends (Vautard and Ghil, 1989; Vautard et al., 1992; Ghil and Mo, 1991a, b).
The particular Monte Carlo approach to S/N separation introduced by Allen (1992) has become known as Monte Carlo SSA (MC-SSA), and detailed description can be found in Allen and Smith (1996; AS hereafter). See also the review papers of Ghil and Yiou (1996), and Ghil and Taricco (1997).
Monte Carlo SSA can be used to establish whether a given timeseries is
linearly distinguishable from any well-defined process,
including the output of a deterministic chaotic system, but we will
focus on testing against the linear
stochastic processes which are normally considered as ``noise''.
``Red noise'' is often used to refer to any linear
stochastic process in which power declines monotonically with
increasing frequency, but
we prefer to use the term to refer specifically
to a first-order auto-regressive, or AR(1), process ![]() whose
value at a time t depends on the value at time t-1 only,
whose
value at a time t depends on the value at time t-1 only,
![]()
where ![]() is a gaussian-distributed white-noise process, for which
each value is independent of all previous values,
is a gaussian-distributed white-noise process, for which
each value is independent of all previous values,
![]() is the process mean and
is the process mean and ![]() and
and ![]() are constant
coefficients.
are constant
coefficients.
When testing against a red noise null-hypothesis,
the first step in MC-SSA is to determine the red-noise
coefficients ![]() and
and ![]() from the time series X(t) using a
maximum-likelihood criterion. Estimators are
provided by Allen (1992) and AS
which are asymptotically unbiased
in the limit of large N and close to unbiased for shorter series
provided the series length is at least an order of magnitude longer
than the timescale of decay of autocorrelation,
from the time series X(t) using a
maximum-likelihood criterion. Estimators are
provided by Allen (1992) and AS
which are asymptotically unbiased
in the limit of large N and close to unbiased for shorter series
provided the series length is at least an order of magnitude longer
than the timescale of decay of autocorrelation, ![]() .
Based on these coefficients, an ensemble of
surrogate red-noise data can be generated
and, for each realization, a
covariance matrix
.
Based on these coefficients, an ensemble of
surrogate red-noise data can be generated
and, for each realization, a
covariance matrix ![]() is computed. These covariance matrices
are then projected onto the eigenvector basis
is computed. These covariance matrices
are then projected onto the eigenvector basis ![]() of the
original data,
of the
original data,
Since (6) is not the SVD of that realization, the matrix
![]() is not necessarily diagonal,
but it measures the resemblance of a given
surrogate set with the data set.
This resemblance can be quantified by computing the
statistics of the diagonal elements of
is not necessarily diagonal,
but it measures the resemblance of a given
surrogate set with the data set.
This resemblance can be quantified by computing the
statistics of the diagonal elements of ![]() . The statistical
distribution of these elements, determined
from the ensemble of Monte Carlo simulations, gives confidence
intervals outside which a time series can be
considered to be significantly different from a generic red-noise
simulation. For instance,
if an eigenvalue
. The statistical
distribution of these elements, determined
from the ensemble of Monte Carlo simulations, gives confidence
intervals outside which a time series can be
considered to be significantly different from a generic red-noise
simulation. For instance,
if an eigenvalue ![]() lies outside a 90% noise percentile,
then the red-noise null hypothesis for the associated EOF (and
PC) can be rejected with this confidence. Otherwise, that particular
SSA component of the time series
cannot be considered as significantly different from red noise.
lies outside a 90% noise percentile,
then the red-noise null hypothesis for the associated EOF (and
PC) can be rejected with this confidence. Otherwise, that particular
SSA component of the time series
cannot be considered as significantly different from red noise.
Allen (1992) stresses that care must be taken at the parameter-estimation stage because, for the results of a test against AR(1) noise to be interesting, we must ensure we are testing against that specific AR(1) process which maximises the likelihood that we will fail to reject the null-hypothesis. Only if we can reject this (the ``worst case'') red noise process, can we be confident of rejecting all other red noise processes at the same or higher confidence level. A second important point is test multiplicity: comparing M data eigenvalues with M confidence intervals computed from the surrogate ensemble, we expect M/10 to lie above the 90th percentiles even if the null hypothesis is true. Thus a small number of excursions above a relatively low percentile should be interpreted with caution. AS discuss this problem in detail, and propose a number of possible solutions.
The MC-SSA algorithm described above can be adapted to eliminate known periodic components and test the residual against noise. This adaptation provides sharper insight into the dynamics captured by the data, since known periodicities (like orbital forcing on the Quaternary time scale or seasonal forcing on the intraseasonal-to-interannual one) often generate much of the variance at the lower frequencies manifest in a time series and alter the rest of the spectrum. Allen and Smith (1992) and AS describe this refinement of MC-SSA which consists in restricting the projections to the EOFs that do not account for known periodic behavior. This refinement is implemented in the SSA-MTM toolkit, where it is referred to as the "Hybrid Basis" (see the Toolkit Demonstration section below).
|
|
|
|
|